

Home assistant utilise par défaut la base de donnée SQlite , l’avantage de cette base par rapport aux bases de données traditionnelles et quel est directement intégré à Home Assistant . Les déclarations , tables index et données sont stockées dans un unique fichier.
Ce fichier , est enregistré par défaut dans le dossier homeassistant ou config selon votre installation , sous le nom : home-assistant_v2.db. Ce fichier peut très vite atteindre une taille importante de plusieurs Go , si on laisse les valeurs par défaut dans home assistant. Cela à une incidence sur la sauvegarde, qui grossit très vite et l’usure prématurée de la carte SD si vous en utilisez une et même jusqu’à ralentir votre système.
Cet article , va montrer comment alléger ce fichier et comment réaliser des sauvegardes automatiques de HASS.IO très facilement.
Paramètrage base de données
Dans l’installation par défaut de home assistant , la base de données utilisée est SQLite . Pour parcourir ce fichier ou exécuter des requêtes dessus, il vous faut installer soit les outils en lignes de commande : SQLite Tools , soit l ‘explorateur de base de données SQLite .
Dans la documentation dédié à la base de données Home assistant , ils expliquent comment utiliser SQLite tools en ligne de commande.
Par exemple , il est très facile de voir quels sont les données qui utilisent beaucoup d’espace dans la base par l’execution de la requête SQL : ci dessous la liste des 20 entités les plus enregistrés.
SELECT entity_id, COUNT(*) as count FROM states GROUP BY entity_id ORDER BY count DESC LIMIT 20Ci dessous le résultat de la requête sur ma base de donnéee MariaDB ( réalisé via phpmyadmin ).
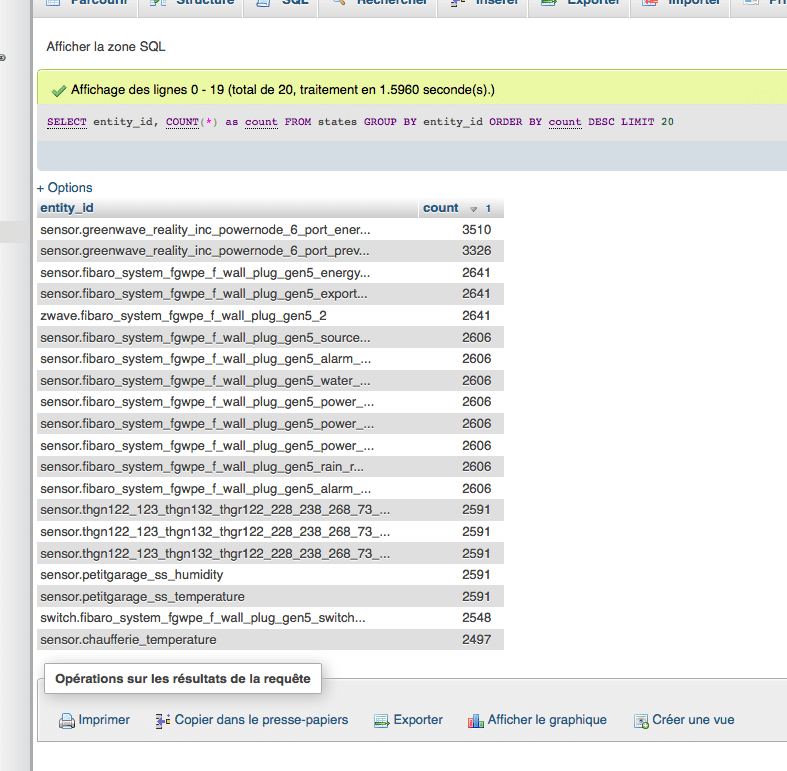
Cette requête va me permettre d’identifier facilement, quelles sont les entités enregistrées qui ne me sont pas utiles.
Aujourd’hui le but de cet article est de parler de l’optimisation de la base afin de générer des sauvegardes légères et ne pas ralentir HA.
Home Assistant utilise SQLAlchemy (ORM) , qui lui permet d’être compatible avec toutes les bases de données prenant en charge ce protocole comme MySql ,MariaDB ,PostgreSQL ,Microsoft SQL server et bien sur SQLite.
Pour ma part, j’utilise MariaDB dans un conteneur séparé ,plutôt que d’utiliser le plugin MariaDB inclus dans Hass.IO ( addon-store )

j’ai préféré installer mariaDB de cette façon , afin de sortir la base de données de la sauvegarde et éviter de me retrouver avec des sauvegardes de Hass.io de plusieurs centaines de Mo voire plusieurs Go. Par exemple mon dernier snapshot ne pèse que 15Mo.

Ce qui permet en cas de restauration de Hass.io de ne pas réinstaller la base de données, il est même possible de faire tourner deux instances de home assistant sur la même base.
La sauvegarde de la base de données est effectué à part, voir en fin d’article.
Une autre commande SQL utile , permet de supprimer un enregistrement précis.
DELETE FROM states WHERE entity_id="zwave.fibaro_system_fgwpe_f_wall_plug_gen5_2"Cette requete SQL , permet de supprimer tous les enregistrements liés à l’entité : zwave.fibaro_system_fgwpe_f_wall_plug_gen5_2. Si je veux me débarrasser définitivement des enregistrements de cette entité , il faudra que je le précise dans l’intégration recorder.
Recorder
L’intégration RECORDER , permet de choisir le type de base de données et les enregistrements désirés. Comme indiqué dans la documentation de Home assistant :
Cette intégration enregistre en permanence les données. Si vous utilisez la configuration par défaut, les données seront enregistrées sur le support sur lequel Home Assistant est installé. En cas de Raspberry Pi avec une carte SD, cela peut affecter le temps de réaction de votre système et l’espérance de vie du support de stockage (la carte SD). Il est donc recommandé de stocker les données ailleurs (par exemple, un autre système) ou de limiter la quantité de données stockées (par exemple, en excluant les appareils).
Home Assistant
Il est donc important de bien sélectionner les données à enregistrer et d’envisager de déplacer sa base de données.
Pour paramétrer cette intégration, il faut commencer par ajouter le mot clef recorder au fichier de configuration.yaml .
# Example activation recorder dans configuration.yaml
recorder:Les options possibles de recorder sont :
- db_url : L’url qui pointe vers votre base de données
- purge_keep_days: Indication du nombre de jours d’historique à conserver dans la base pour la purge ( par défaut 10 ).
- auto_purge: Purge automatiquement la base tous les matins à 04h12 ( heure locale ).La purge empêche la base de données de croître indéfiniment, ce qui prend de l’espace disque et peut ralentir Home Assistant.
Par exemple mon integration recorder.
# Example recorder dans configuration.yaml
# base de donnee Mariadb ( installation dans docker )
recorder:
db_url: mysql://user:password?@server_ip/homeassistant?charset=utf8
purge_keep_days: 30
auto_purge: trueLes deux prochaines options , vont me permettre de filtrer les entités à sauvegardé.
- include : permet d’inclure des domaines ou des entités
- exclude : permet d’exclure des domaines ou des entités ainsi que des événements.
Chacune de ses options disposent de trois mots clefs commun : domains, entities et entity_globs l’option exclude dispose en plus du mot clef : event_types.
- domains: permet de choisir un domaine d’entités , par exemple le domaine light , regroupe toutes les entités de type lumière.
Chaque installation de HA , peut avoir des domaines différents en fonctions des intégrations installés. Afin d’avoir la liste des domaines actifs de votre Home Assistant , il est possible d’en connaitre la liste en utilisant les modèles jinja2 .
Allez dans le menu Outil de développement / modèle et coller ce code au début de l’éditeur :
{%- set unique_domains = states | map(attribute='domain') |list | unique | list -%}
{%- for domain in unique_domains -%}
- {{domain + "\n"}}
{%- endfor -%}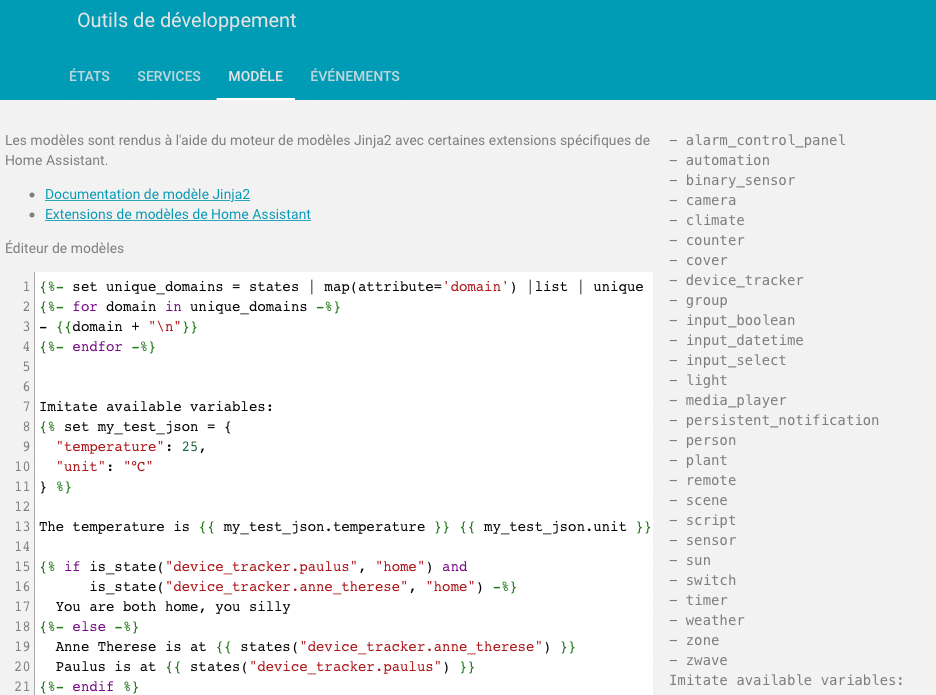
Le résultat peut être different en fonction de votre installation.
- entities: Permet de lister les entitées à garder ou à exclure. Comme pour les domaines , il est possible de connaitre la liste de toutes les entitées par le modéle jinja suivant.
Liste des entitées:{{ "\n"}}
{%- for state in states -%}
- {{state.entity_id + "\n"}}
{%- endfor -%}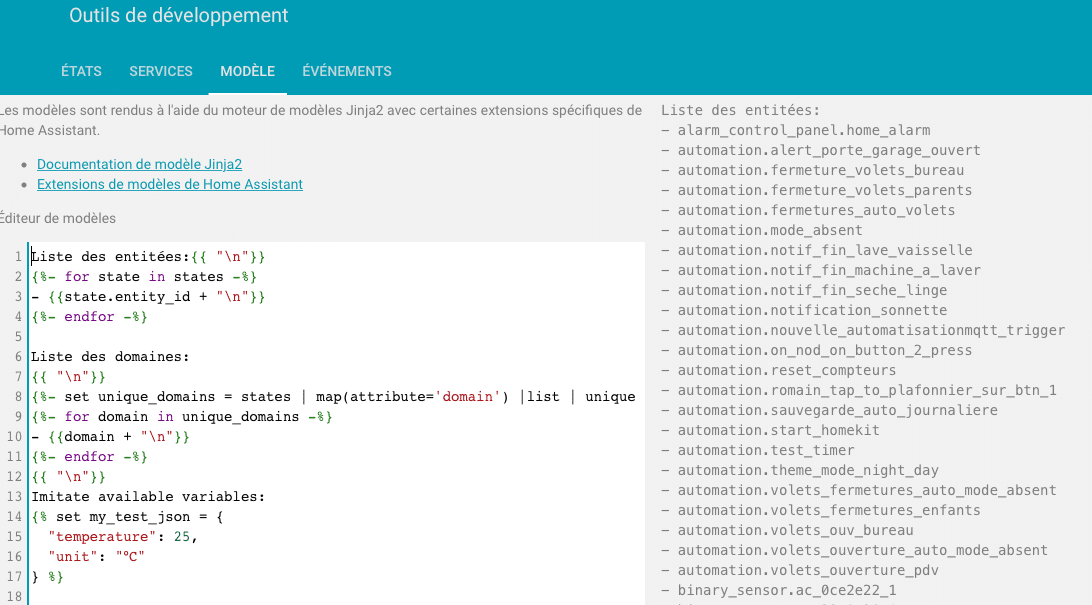
- entity_globs: Permets de sélectionner un groupe d’entité en fonction d’un modèle . Par exemple le modèle : sensor.ups_* sélectionnera toutes les entités commençant par « sensor.ups_« .
- event_types: Uniquement pour exclure , permet de désactiver les enregistrements liés aux événement. Par exemple call_service va désactiver tous les événement généré par les appels de service.
Il n’y a pas de recette miracle pour la partie include et exclude , chaque installation de Home assistant étant différente. Je vous conseille dans un premier temps de n’inclure que ce qui vous semble essentiel ou d’exclure ce que vous ne voulez pas enregistré . Puis petit à petit d’ajouter des exceptions en fonction de vos besoins.
Les règles à connaitre
- Si ni Include ni exclude : tout est enregistré ( comportement par défaut )
- Si seul include est renseigné : Seuls les enregistrements spécifiés seront enregistrés
# Example configuration.yaml entry with include
recorder:
include:
domains:
- sensor
- switch
- media_playerDans cet exemple , toutes les entités de types sensor , switch et media_player seront enregistrés.
- Si seul Exclude est spécifié : Tout est enregistrés sauf ceux spécifiés dans exclude
# Example configuration.yaml entry with Exclude
recorder:
exclude:
domains:
- automation
- updater
entity_globs:
- sensor.weather_*Dans cet exemple , seuls les automatisations , le service de mise a jour et toutes les entités dont le nom commence par : sensor.weather_ ne seront pas enregistrés.
- Si include et exclude sont renseignés alors :
- Dans le cas de include :
- L’entité est enregistré si inclus dans le domaine , et n’est pas explicitement exclue par l’option entities ou entity_glob
- L’entité est enregistré si inclus dans l’option entity_globs , et n’est pas explicitement exclue par l’option entities ou entity_glob ni ne fait partie du domaine exclu.
- L’entité est enregistré si inclus avec option entities.
- Dans le cas Exclude :
- L’entité ne sera pas enregistré si son domain est exclu ou si elle correspond à un modele exclu par l’option ( entity_glob) ou si elle est explicitement nommée par entities.
- Si l’entité est renseigné dans include et exclude , l’option exclude sera ignorée et l’entité sera enregistré.
- Dans le cas de include :
Ci-dessous un exemple avec include et exclude
# Example configuration.yaml entry with include and exclude
recorder:
include:
domains:
- sensor
- switch
- media_player
exclude:
entities:
- sensor.last_boot
- sensor.date
entity_globs:
- sensor.weather_*Dans cet exemple , les entités faisant partie des domaines sensor , switch et media_player seront enregistrés . Sauf les entités : sensor.last_boot , sensor.date et toutes les entités commençant par sensor.weather_
ci dessous l’exemple de mon fichier recorder
######################################
### entités & domaine a sauvegarder #
######################################
recorder:
db_url: !secret url_db
purge_keep_days: 30
auto_purge: true
include:
domains:
- sensor
- switch
- binary_sensor
- light
- person
- alarm_control_panel
- climate
- group
- zone
- plant
entities:
- sensor.hem_energy_energy_4
- sensor.hem_energy_power_3
exclude:
domains:
- automation
- updater
- media_player
- camera
- counter
- cover
- device_tracker
- input_datetime
- input_boolean
- persistent_notification
- remote
- scene
- script_started
- sun
- weather
- zwave
event_types:
- service_removed
- service_executed
- platform_discovered
- homeassistant_start
- homeassistant_stop
- feedreader
- service_registered
- call_service
- component_loaded
- automation_triggered
- script_started
- timer_out_of_sync
entity_globs:
- sensor.hem_*
- sensor.aeon_labs_zw095_*
- light.ruban_*
entities:
- sun.sun # sensor position soleil
- sensor.last_boot # sensor système
- sensor.date # sensor date
- sensor.time # sensor time - peut générer une entree à chaque seconde
- sensor.en_ligne
- light.tv_salon_1Apres plusieurs mois d’utilisation la taille de ma base de donnée est de moins de 200 Mo
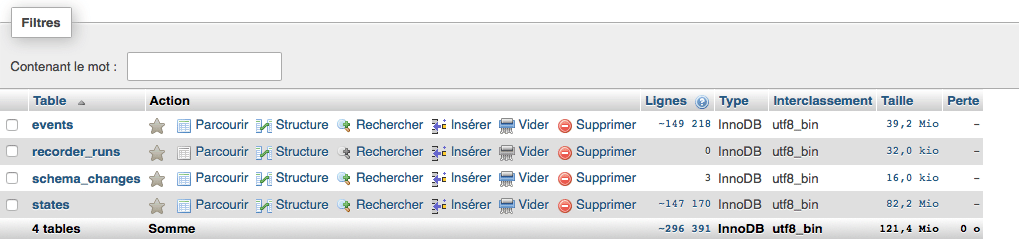
Attention : L’historique et le journal sont dépendants du service recorder , ces deux services ne pourront pas afficher d’information d’une entité non présente dans votre base de données.
HISTORY ( Historique )
Cette intégration permet de masquer ou d’afficher certaines entités , il sera possible alors de n’afficher l’historique que des entités à suivre.Par défaut l’historique affiche toutes les informations contenues dans la base de données.
Elle se paramètre de la même façon que l’intégration recorder ( options include et exclude et sous clefs entities et domains ) .
exemple :
# Example configuration.yaml entry using specified entity display order
history:
use_include_order: true
include:
entities:
- sun.sun
- light.front_porchDans cet exemple seul les entités sun.sun et light.front_porch sont affichés , cela va permettre de vérifier que la lumière extérieure s’allume et s’éteint bien en fonction de la position du soleil.
Le paramètre : use_include_order: true permet de forcer l’ordre d’affichage des entités.
LOGBOOK ( ou journal )
L’intégration du journal de bord montre tous les changements survenus dans votre HA dans l’ordre chronologique inverse.
Par défaut, aucune entité ne sera exclue. Pour limiter les entités affichées dans le journal de bord , vous pouvez utiliser les paramètres include et exclude , selon la même règle que Recorder ou history.
Les mots clefs : entities , entity_globs et domains sont possibles.
exemple : montre uniquement les entités des domaines sensor et switch
# Example to show how to include only the listed domains in the logbook
logbook:
include:
domains:
- sensor
- switch
- logbookLe journal , comme l’historique ne pourra afficher que toutes les entités enregistrées dans recorder. Si recorder exclus un domaine ou une entité , il ne sera pas possible de l’afficher dans le journal ou dans l’historique.
Astuce:
Il est possible d’ajouter une entrée dans le journal via le service logbook.log. Ce service permet d’insérer des informations personalisées dans le journal. Ces infos peuvent êtres associées à un domaine et une entité ou simplement être affecté au domaine logbook ( il faudra alors ajouter ce domaine si un filtre include a été ajouté à logbook. )
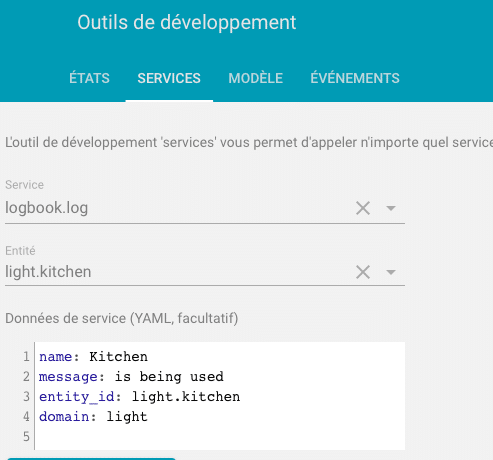
exemple : utilisation dans scénario
automation:
- alias: "Test journal"
trigger:
platform: time
at: "18:50:46"
action:
service: logbook.log
data:
name: "test logging: "
message: >
{{states.sensor.netatmo_exterieur_temperature.state}}Si entity_id et domain non précisé , le domain sera affecté à logbook ( il ne faut donc pas oublier d’ajouter logbook à domains si include activer dans l’intégration logbook. )
Ce qui donne dans le journal :
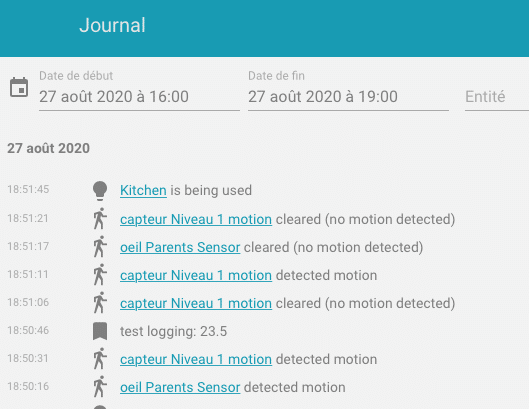
Selon si le domaine est précisé ou non , l’affichage des icônes et raccourcis vers l’entité est different.
Sauvegarde des fichiers de configuration Hass.io
Sauvegarde manuel
Sauvegarde des journaux de configuration et addon Hass.io , par le biais du menu supervisor / snapshot.
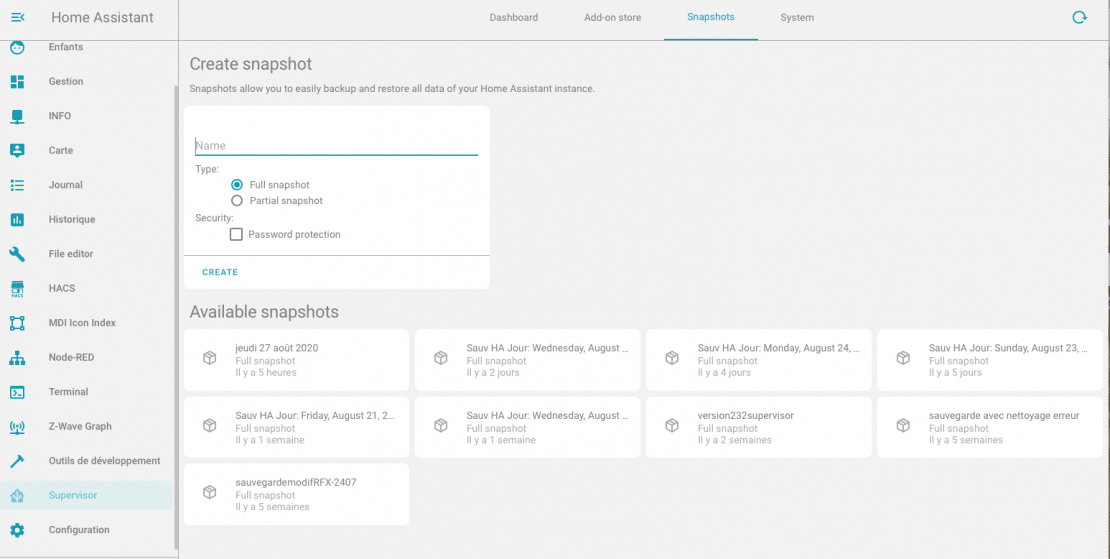
Les snapshot copie l’ensemble des fichiers de configuration ( base de données incluss si sqlite ) et tous les addons ajoutés. Chaque snapshot , permet d’être téléchargé ou restauré.
Les snapshots sont enregistrés dans le dossier backup.
Restauration
Pour restaurer une sauvegarde sur une nouvelle installation il suffira de coller le snapshot ( xxxxxxxx.tar ) dans le dossier backup. Ce dernier va apparaitre dans le menu snapshot , il suffit alors de le sélectionner et de cliquer sur restore selected.
Sauvegarde automatique
il est assez simple de programmer une sauvegarde automatique en utilisant le service snapshot.snapshot_full , par exemple ci dessous une sauvegarde hebdomadaire tous les dimanches a 02H00 du matin
## Sauvegarde via service snapshot_full
## sauvegarde tous les dimanche à 02H00 du matin
automation:
- alias: Sauvegarde hebdo - Dimanche 02:00 heures
trigger:
platform: time
at: '02:00:00'
condition:
condition: time
weekday:
- sun
action:
service: hassio.snapshot_full
data_template:
name: "Sauv HA Dimanche : {{now().strftime('%d.%m.%y')}}"Sauvegarde base de données MariaDB ( installation docker )
Une petite astuce pour sauvegarder automatiquement la base de données. Si vous êtes dans le même cas que moi , et que vous avez préféré installé la base de données de façon indépendante ( hors hass.io – hors addon ) , dans un conteneur indépendant de votre docker.
Comme expliqué dans la documentation du docker hub consacré à MariaDB , il est possible de réaliser une sauvegarde ou une restauration en utilisant la commande docker exec.
Extrait de la documentation :
// backup database dans docker
$ docker exec some-mariadb sh -c 'exec mysqldump --all-databases -uroot -p"$MYSQL_ROOT_PASSWORD"' > /some/path/on/your/host/all-databases.sql
//restore database sous docker
$ docker exec -i some-mariadb sh -c 'exec mysql -uroot -p"$MYSQL_ROOT_PASSWORD"' < /some/path/on/your/host/all-databases.sqlMise en place de cette commande pour le conteneur mariadb installé dans docker synology.
Exemple : Voici une vue du docker synology , sur lequel est installé hass.io et mariaDB.

En prenant comme paramétre les éléments ci dessous :
- Nom du conteneur mariaDB : mariadb
- utilisateur root MariaDB: root
- mot de passe root Mariadb: password
- nom de la base de donnée : hassio
La commande suivante me permet d’effectuer une sauvegarde de ma base de donnée :
docker exec mariadb sh -c 'exec mysqldump -u root -ppassword hassio' | gzip > /volume1/docker/DB/ha-$(date +"%d-%m-%y").gzipQue fait cette commande :
docker exec mariadb sh -c : execute une commande bash sur le conteneur mariadb
exec mysqldump : execute la commande mysqldump avec les paramètres suivants
-u root : utilisateur root de la base de donnée
-ppassword : Mot de passe de la base de donnée ( Attention : -p et password sont collé – aucun espace – : -ppassword )
| gzip : Compresse le résultat .
> /volume1/docker/DB/ha-$(date + »%d-%m-%y »).gzip : et écrit le tout dans le dossier du synology /volume1/docker/DB/ avec le nom du fichier en fonction de la date du jour .
Automatisation de la sauvegarde :
Afin de ne pas avoir à lancer la commande manuellement , il est possible sur un NAS Synology de programmer une tache .
Panneau de configuration / Planificateur de taches / Créer une tâche.
Tache planifiée / script définit par utilisateur
Donner un nom et choisir utilisateur : root
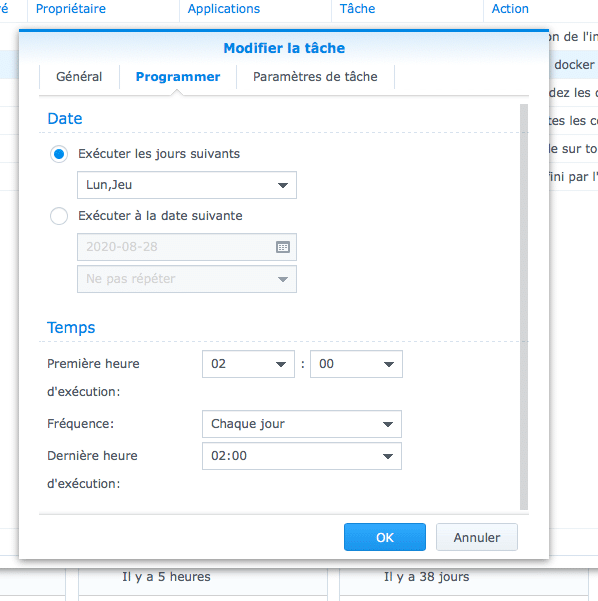
Dans l’exemple ci dessus , j’ai choisi d’executer mon script deux fois par semaine ( lundi et jeudi à 02H00 du matin ). Dans la partie suivante je copie mon script.
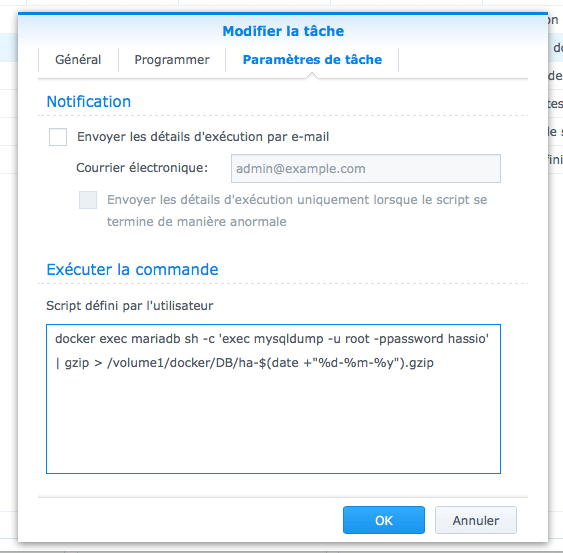
Puis ok pour enregistrer. Vous pouvez verifier le bon fonctionnement en sélectionnant la tâche nouvellement créée et clic sur executer.
BONUS : Suppression auto des anciennes sauvegardes
Afin de ne pas saturer son disque , il est possible de rajouter un script qui nettoie régulièrement ce dossier, afin de supprimer les sauvegardes de plus de trente jours.
Il suffit de copier ce code , dans la fenetre de script de la tâche.
docker exec mariadb sh -c 'exec mysqldump -u root -ppassword homeassistant' | gzip > /volume1/docker/DB/ha-$(date +"%d-%m-%y").gzip;
find /volume1/docker/DB/ -type f -atime +30 -name "*.gzip" -delete;La commande find , cherche les fichier ( gzip ) créé il y a plus de 30 jours ( -atime +30 ) et les supprime automatiquement.
Restauration base de donnée :
Pour la restauration de la base de données , la commande est trés similaire . Ajout de l’option -i à exec et utilisation de mysql à la place de mysqldump . Attention à la direction du fichier qui change ( < à la place de > ).
docker exec -i mariadb sh -c 'exec mysql -u root -ppassword hassio' | gunzip < /volume1/docker/DB/ha-28-08-20.gzip
Commentaire sur “Home assistant : Optimisation et sauvegarde de la base de données.”